scouty代表の島田です。 実はscoutyではサービス上で実用するに至れていませんが、技術選定の段階で調査したので、最近人気も出ているニューラルネットによる Dependency Parsing についてまとめてみました。 前半は、自然言語処理の基本となる大きな流れに関しても触れていますので、NLPに詳しくなくてもご理解いただけると思います!
自然言語処理の基礎:意味解析とは?
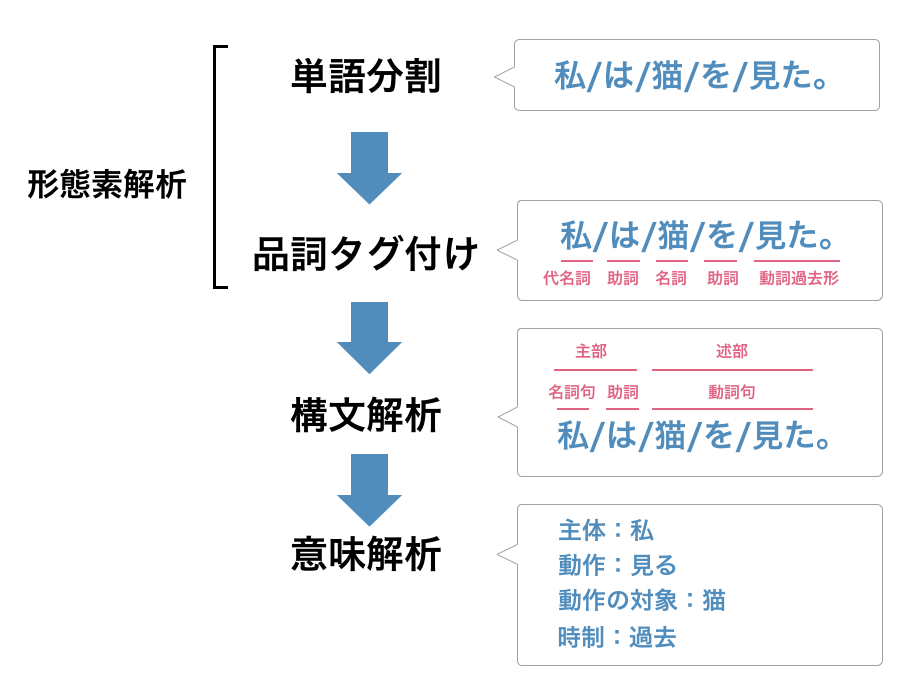
そもそも自然言語処理といってもいろいろな分野があります。ミクロな部分に入る前に、まずは全体の流れを理解しましょう。 自然言語処理は、大まかに上の図のような流れになっています。これは日本語に限らずどの言語にも通ずる一般的なプロセスになっています。
各プロセスは次の通りです。
- 形態素解析:まずは、与えられた文章の単語を分かち書き、品詞を推定する(厳密には、品詞だけではなく時制なども判断します。)
- 構文解析:品詞の上位に存在する主部・述部・名詞句・動詞句などの構造を発見する
- 意味解析:文内の主体や動作の対象はなにかという意味を推定する
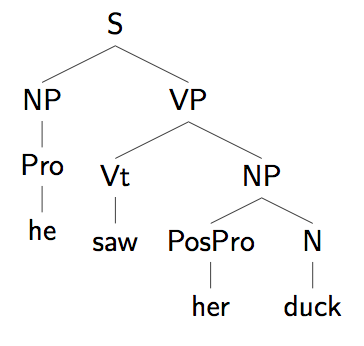
つまり、自然言語処理における構文解析とは、単語ごとの粒度で文章に木構造のような意味解析を行うのに都合の良い構造を見出すことです。 最も代表的かつ一般的な構文解析は、次の図のような文の構成要素(名詞句・動詞句・・とか)・品詞に基づいた構文解析でしょう。これは文脈自由文法(「文→名詞句 動詞句」「名詞句→冠詞 名詞 | 代名詞 | ..」のような生成規則を逆向きに適用して木を作る)を使って構成されます。
Dependency Parsing とは?
構成要素ベースの構文解析では名詞句・動詞句のような構成要素を仮定しなければいけませんが、これは完全に言語依存で、言語によっては存在しない構成要素や品詞がある(日本語には冠詞や前置詞が無いとか)ため、言語横断的に適用することができません。
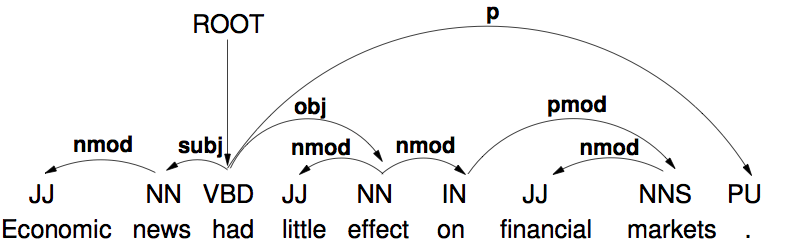
そこで使えるのが上のような Dependency Parsing (DP) です。Dependency Parsing は文中の依存関係 Dependency に基いて構文解析を行います。これの何が有益かというと、構文解析の下流工程である意味解析が非常に行いやすいことです!つまり、例えば動詞の部分では関係に方向がついているので、何が動作の主体で何が客体か、などのような関係を捉えやすい。
ただし、Dependency Parsing においては、以下の3つの条件を満たすことが約束されなければいけません。
- 各ノード(単語)の流入エッジは必ずひとつでなければいけない(流出エッジは何個でも良い)
- よって非環式である(循環閉路がない)
- 連結グラフである
なお、上のように表した時に枝が交差しないように描けるとき、その Dependency Tree は Projective(投影性?)である、と表現します。英語に対する Dependency Tree は基本的に Projective になります(が、他の言語では成立しないことがある)。
ニューラルネットによる Dependency Parsing
Dependency Parsing の手法として、最大全域木問題(Maximum Spanning Tree)を解くことで Dependency Tree を求めるという非ニューラルネットな手法があります。つまり、スコア(あらかじめ人間が作ったスコアのルールに基いて木にスコアをつける)を最大化する木構造を探し、それを Dependency Tree とする方法(2005年頃にアルゴリズムができている)がありました。しかし、これは人間が作ったルールに基づくので恣意的であり、そのルールに性能が依存する上それは言語依存の部分があるので、近年(2014年頃)ニューラルネットワークで自動的に Dependency Parsing を行う手法が提案されました。
それは MALT パーサーと呼ばれていて、基本構造はよくコンパイラなどで使われるのと同じ Shift-Reduce 型のパーサーです。つまり、下図のように文頭からスタックにどんどん単語を追加していき(SHIFT)、Dependency を発見したらスタックから単語を取り除いて(REDUCE)A に Dependencyを 追加する(A は Dependency の集合)という仕組みです。
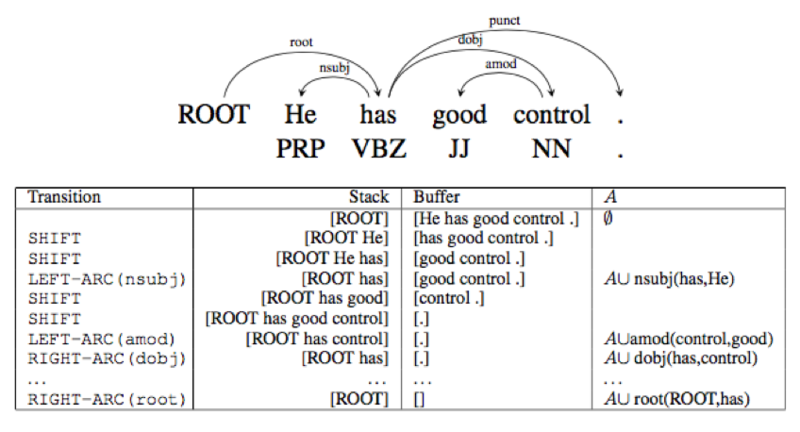
遷移(Transition: SHIFT か REDUCE かの判断)は手作りの特徴とルールに基いて行われるのが伝統的なやり方でしたがが、これをニューラルネットワーク(NN)によって自動化しよう、というのが ニューラルネットワーク による Dependency Parsing の基本的なアイディアです。
基本構造:もう少し詳しく
学習の目的は \(i\) 番目の正しい遷移 \(t_i\in T\) を予測することであり、その際に使えるのは以下のような情報です。なお、これらを configuration (\(c_i\))と表します。
- 対象単語とその品詞
- Dependency の矢印の先の単語と、そのラベル
- スタックとバッファでの単語の位置
これをニューラルネットによって判断するにはどうすればよいでしょうか? 単純に、それらのベクトル表現をすべてくっつけたものを入力にしてやれば良いのです!
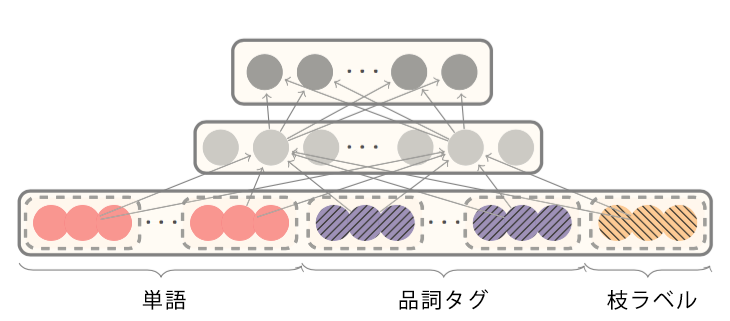
つまり、入力ベクトルは \([\boldsymbol{x}^w, \boldsymbol{x}^t, \boldsymbol{x}^l ]\) となり(それぞれ順に単語・品詞タグ・枝ラベル)、隠れ層は以下の式で表されます:
$$\boldsymbol{h} = {(\boldsymbol{W}^w_1\boldsymbol{x}^w+\boldsymbol{W}^t_1\boldsymbol{x}^t+\boldsymbol{W}^l_1\boldsymbol{x}^l+\boldsymbol{b}_1)}^3$$
面白いのは、活性化関数に3乗(立方)を使っていることです。NNでは一般的ではありませんが、このタスクでは一番性能が良かったようです[1]。 出力レイヤーは通常通りソフトマックスを用います。出力レイヤーの次元数は遷移の数(ラベルも加味した遷移なので、SHIFT と REDUCEの2種だけということではなく、REDUCE の場合は上図のように LEFT-ARC (n-subj) や LEFT-ARC (amod) など、結構多い)で、一番値の大きかったノードの遷移を選択する、という仕組みです。
単語・品詞タグ・枝ラベルはすべて埋め込み表現 (embedding. 分散表現の一種) で表されている。品詞タグの分散表現というのは、単語の類似度と同じように例えば「"複数名詞"は"冠詞"より"単数名詞"に近い」などのような類似度が反映されたベクトル表現のことです。ただし、この embedding は通常の単語表現の embedding とは異なり、対象単語だけではなくスタック・バッファ内の数語を混ぜあわせて作られた表現です。詳しくは[1]参照。 品詞を embedding として表現してしまうの発想として新しいですね。品詞を one-hot として表すよりも。類似度も定義できるので精度が上がりそうです。
正しい遷移とconfigurationのペア \((c_i, t_i)\) のデータセットから得て、入力 \(c_i\) から出力 \(p_{t_i}\) を順伝播で作成し (\(p_{t_i}\) は遷移 \(t_i\) が起こる確率)、誤差を次の式で計算します(普通のクロスエントロピー)。
$$L(\theta)=-\sum_i\log p_{t_i} + \frac{\lambda}{2}||\theta||^2$$
\(\theta\) はパラメータ、二項目はL2正則化項、学習方法は普通のNNと同じバックプロパゲーションを使います。
まとめ
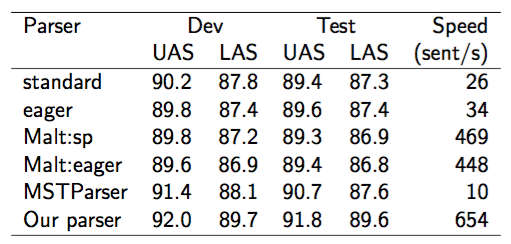
[1]から引用したパーシングの結果は上の表の通りです。 伝統的なMALTパーサー(人間のてづくり特徴ベース)よりも、過去のいずれのパーサーよりも良い結果(遅いですが……)を出しているのがわかります。
また、今回は扱わないですが、上述の最大全域木 MST ベースのパーサーの(特徴ベースでなく)NN 版もあるようです(これは2015年に出たもので、比較的新しい)。 ニューラルネット・Deep Learning(本例は1層なので深層ではないが)が人間のつくった特徴量ベースの手法を蹂躙するという構図は画像認識の領域のみならずいろいろなところで起こっているということが理解できますね。 scoutyでも、高度な意味解析を要する場面では今後使っていく可能性は高いですね。
参考文献
[1] Chen, Danqi, and Christopher D. Manning, 2014, A fast and accurate dependency parser using neural networks, In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 740–750. Doha. http://cs.stanford.edu/people/danqi/papers/emnlp2014.pdf