代表の島田です。 今回は、今後scoutyでもスカウトメールの返信率予測などに利用していこうと考えているCNN(畳み込みニューラルネットワーク)の自然言語処理分野への応用をご紹介します。 画像認識に使われることも多いCNNですが、最近は自然言語処理への応用もさかんです。
CNNとは
畳み込みニューラルネットワーク(Convolutional Neural Network:以下CNN)は、画像認識でハイパフォーマンスを叩きだしたことで知られるネットワークアーキテクチャで(1999年ごろから存在はしたが、注目を集めたのは2012年以降?)、画像認識で用いられてきましたが自然言語にも応用することができます。というか、マトリックスを入力とする問題には基本すべて応用できます。
CNN自体を解説したソースは他にたくさんあるので、CNNに関してはそちらを参照するほうが早いでしょう。ただ、ものすごく簡単に言うと従来のニューラルネットワークは下図のようなフルコネクト(隠れ層のどのユニットも入力層のすべてのユニットに接続されている)であり、画像のような2次元の入力も無理やり1次元のベクトルに引き伸ばして扱っていたのに対して、
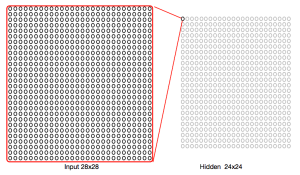
CNNでは、隠れ層のある一点が入力のある領域に対応しているという重みを持っています。
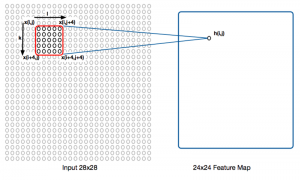
これによって、平行移動にロバストになるという特徴がある。重みの形からネットワークアーキテクチャまで全く通常のNNと異なります。詳しくは 定番のConvolutional Neural Networkをゼロから理解する - DeepAge などの記事を参照しましょう。
CNNを自然言語処理に応用する
畳み込みニューラルネットワークを自然言語処理に応用するには、文をマトリックスに見立てます。つまり、単語を適当な分散表現で表せば単語はすべて同じ次元のベクトルで表せますが、これを単に文に登場する順番に並べてやれば、下図のように文をマトリックスとして表現できるというわけです。
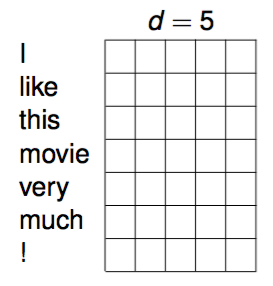
dは単語のembeddingの次元数で、通常はもっと大きいはずですがここでは簡単のため5とします。マトリックスの高さは文の中の単語数と等しくなるので、文ごとにマトリックスのサイズは異なります。
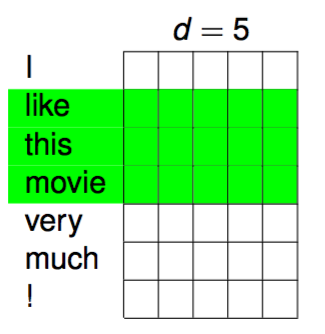
フィルター(重み)を上図のように適当な長さに定めてマトリックスを上からスキャンすることで通常のCNNと同じように特徴マップ(Feature Map)を作ることができます。フィルターのウィンドウサイズ(フィルタリングする領域の長さ、上図では3)は特徴マップごとに変更します。つまり、ウィンドウサイズ2の特徴マップ、ウィンドウサイズ3の特徴マップ、ウィンドウサイズ4の特徴マップ… などのように複数作ることでマップごとに異なる特徴を学習することができます。 ところで、ウィンドウサイズはN-gramのNに当たります。つまり、サイズ2はbi-gram, サイズ3はtri-gramに対応するということですね。 ネットワーク全体のアーキテクチャは以下のような形になります。
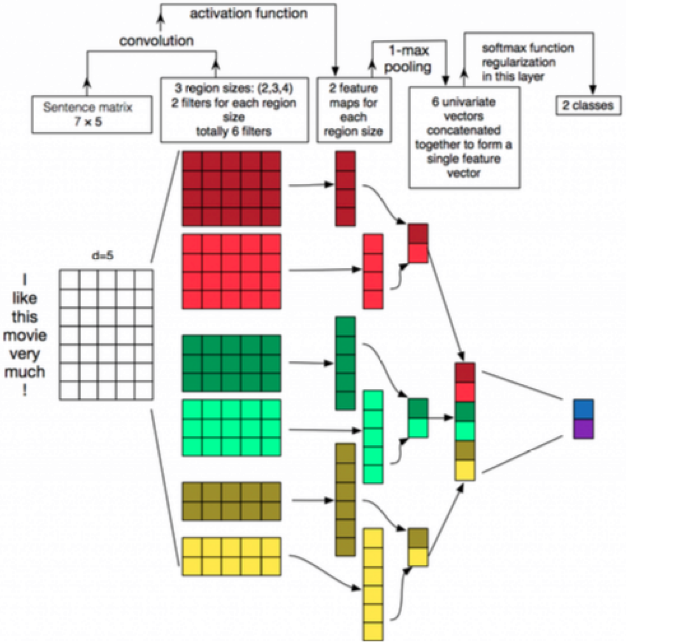
フィルター(2列目)と入力(1列目)を畳み込んでつくった特徴マップ(左から3列目)をプーリングし、各プーリング層を連結させてひとつのベクトルを得る。これが文の分散表現Embeddingになります。これの後ろのレイヤーに何層か挟んで、最終出力のレイヤーをクラスの確率分布とすれば、文を入力としてクラスを出力とする識別器をつくることもできます。
まとめと性能
[1]の実験によると、CNNによるモデルは、映画レビューや製品レビュー文のセンチメント解析(ポジティブ/ネガティブの解析)において、下図のような結果を出しています。この研究では、CNNを従来の他モデルすべてと比較しています。
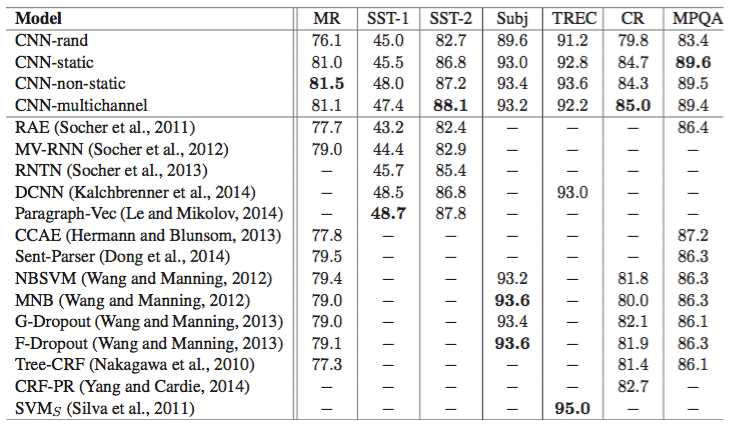
MR, SST, TREC, CR ..などは各タスクで、数字が精度(100%中)です。左列がモデルで、上段の4つのCNNは、CNNバージョンの異なるモデルを表しています(たとえば単語の分散表現のモデルの違いや、プリトレーニングの有無など)。7タスク中4つでCNNが最高の成果を出す結果となっています。
つまり、現状文の分散表現にはいろいろなモデルがありますが、2014年の時点ではそれらを含めて基本的にCNNがベスト(あくまでクラス識別問題ですが)である、ということですね。
scoutyでの応用例
scoutyでは今後、スカウトメールの文面を今回紹介したような方法でマトリックス化し、
- そのメールの開封有無
- そのメールの返信有無
- そのメールを受け取った人が実際に転職に繋がったか
のようなデータを教師データとして、CNNなどの手法を使って返信率等を予測する、といった事にチャレンジしていこうと思っています。それを使って、スカウトメールの自動レビューや自動添削などに活かして行こうと考えています。 今回紹介したのは単語単位でのCNNですが、日本語の場合だと文字のone-hotベクトルをつなぎ合わせてインプットをつくるという文字単位のCNNもあるようです。言語や問題に応じてどのCNNモデルが適切か、実際のデータを使って比較してみたいですね。
参考文献
[1] Yoon Kim, Convolutional Neural Networks for Sentence Classification, EMNLP-2014 http://emnlp2014.org/papers/pdf/EMNLP2014181.pdf