scouty 代表の島田です。 トピックモデルで単語の分散表現 - 理論編 - scouty AI LAB では、局所表現・分散表現の違いに関して説明しましたが、「単語の分散表現と同じように、文*1の分散表現を作るにはどうすればよいか?」というのが今回のテーマです。 CNNで文の識別タスクを解く - scouty AI LAB でもCNNによって文の分散表現を作る方法を扱いましたが、本記事では Recursive Autoencoder によって文の分散表現を作る方法をご紹介します。
Autoencoder とは何か
Recursive Autoencoder は、 Autoencoder (オートエンコーダー)を組み合わせることによって文の意味表現をひとつのベクトルとして表そうとするモデルです。 Autoencoder というのは、入力ベクトルを受け取ったら、入力ベクトルと全く同一のベクトルを出力することを目的として学習を行う特殊なニューラルネットワークモデルのひとつで、次のような図で表されます。
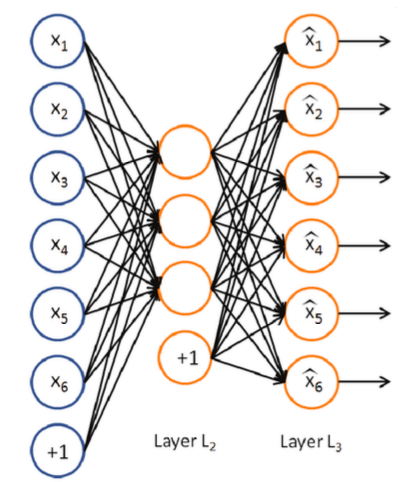
入力次元よりも隠れ層の次元が大きければ入力 \(x_i\) をただ単に出力 \(\hat{x}_i\) に受け流すという自明な解が存在してしまうので、一般的には隠れ層の次元は入力層の次元より小さく設定します。学習が終了したのちに何らかのベクトルを入力すると、隠れ層の値は入力ベクトルの圧縮表現になっています。つまり、隠れ層は「学習した重みと掛け合わせることで入力が再現できるベクトル」であり、隠れ層の次元は入力ベクトルの次元より小さくなっているので、 Autoencoder はベクトルの次元縮約器であると解釈することができます*2。
Autoencoder では入力ベクトルを再現するように学習を行うため、教師データが必要ありません。そのため、 Autoencoder は教師なし学習に分類されます。\(d\) 次元の入力ベクトル \(\boldsymbol{x} = (x_1, \dots, x_d)^T\) に対する Autoencoder の出力を \(\boldsymbol{\hat{x}} = (\hat{x}_1, \dots, \hat{x}_d)^T\) とすると、\(\boldsymbol{\hat{x}}\) は以下のように表されます。
$$\boldsymbol{h} = \boldsymbol{f}(\boldsymbol{W_1}\boldsymbol{x} + \boldsymbol{b_1}),\\
\boldsymbol{\hat{x}} = \boldsymbol{f}(\boldsymbol{W_2}\boldsymbol{h} + \boldsymbol{b_2}).$$
ここで、 \(\boldsymbol{h}\) は隠れ層を表すベクトル、\(\boldsymbol{b_1}\), \(\boldsymbol{b_2}\) はバイアスを表すベクトル、 \(\boldsymbol{W_1}\), \(\boldsymbol{W_2}\) は重みを表す行列です。 また、\(\boldsymbol{f}\) は sigmoid などの活性化関数であり、上式では、ベクトルを入力として同次元のベクトルを出力するものとして定式化しています。
Autoencoder の二乗誤差は
$$L(\boldsymbol{x}, \boldsymbol{\hat{x}}) = ||\boldsymbol{x} - \boldsymbol{\hat{x}}||^2$$
Cross Entropy 誤差は
$$L(\boldsymbol{x}, \boldsymbol{\hat{x}}) = -\sum_{k=1}^d x_k \log \hat{x}_k + (1-x_k) \log(1-\hat{x}_k)$$
と表され、トレーニングなどは通常のNNと同じように行われます。 ちなみに、Autoencoder の最も代表的な使いみちは Recursive Autoencoder ではなく、深層学習のプレトレーニングで使われる Stacked Autoencoder でしょう。こちらに関しては既に扱っている文献が多いので、そちらを参照することをおすすめします。
Recursive Autoencoder
Recursive Autoencoder は、Autoencoder を次のように積み上げます。
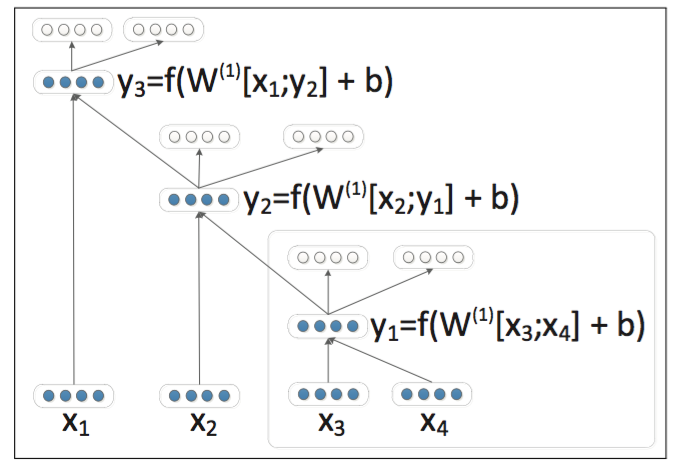
一番下の各 \(\boldsymbol{x}\) は、文内の各単語の分散表現になります。まず文章内の単語を二分木で表すのが第一ステップです。\([\boldsymbol{x}_3; \boldsymbol{x}_4]\) は、ベクトル \(\boldsymbol{x}_3\) と \(\boldsymbol{x}_4\) を単に縦に連結させたベクトルです。この2つのベクトルを Autoencoder で圧縮し、その隠れ層をベクトル \(\boldsymbol{y}_1\) とします*3。次に、 \(\boldsymbol{x}_2\) と \(\boldsymbol{y}_1\) の連結を圧縮し、\(\boldsymbol{y}_2\) を作ります。このように単語を再帰的に圧縮していってできた最後のベクトル \(\boldsymbol{y}_3\) が、この文の分散表現となります。
文から上図のような二分木を作る手法は様々ですが、次のような greedy な手法が用いられることが多いようです。
- 文中の単語数を \(n\) 個として、隣り合う \(n−1\) 個のペアを考える。
- それぞれのペアの Reconstruction Error を計算する。
- その中で一番小さいエラーのペアを選択し、実際にペアを作る。
- ペアをひとつの単語(ノード)に見立てて、1〜3を繰り返す。 隣り合う単語しか見ないので完全なアルゴリズムではありませんが、妥当な時間でそこそこ良い結果を与えることが知られています。
Recursive Autoencoder の性能の尺度である Reconstruction Error (ノード \(y_k\) のエラー) \(E_{\mathrm{rec}}(k)\) は次のように表されます。
$$E_{\mathrm{rec}}(k) = \frac{n_i}{n_i + n_j} ||x_i - \hat{x}_i||^2 + \frac{n_j}{n_i + n_j} ||x_j - \hat{x}_j||^2$$
\(n_i\) はノード \(i\) に含まれている単語数。長い単語の連続ほど再現が難しくなるので、重みをつけています。また、全ツリーのコストは単にこれらのエラーの和とすればよいです。
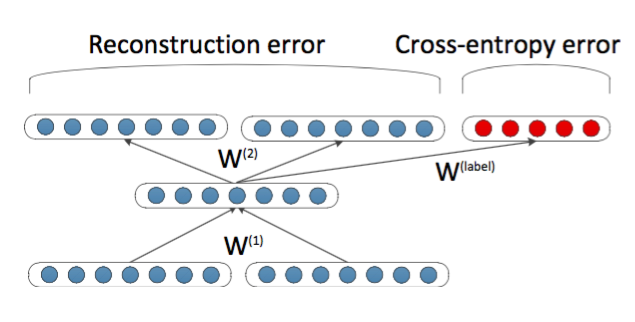
これを使って文のクラス識別器を作る場合、上図のように最終的に得られた \(n−1\) 個の隠れ層 \(y_k\) を入力として、各クラスの確率分布を出力とするニューラルネットを新たに作れば良いわけです。各 \(y_k\) のラベルはすべて文のクラス(ラベル)と同じとします。教師データは該当クラスが1、他が0になっているベクトルになります。 これはあくまでクラス識別や類似性評価に使うものであるので、このベクトル自体から文の意味を抽出して推論などができるかと言われれば、それはできません。しかし、Recursive Autoencoder を使えば文のクラス識別を、人間の手作りの特徴(e.g.センチメント解析ならポジティブ・ネガティブを表す特徴語)を使うことなく行うことができるという点では非常に便利なモデルであると言えるでしょう。
ただし、実運用においては、2017年10月時点では便利なライブラリが無いため、実際にビジネスの場で利用するのは難しそうです。 CNNによる文の分散表現のほうが一般的に文識別などでは精度が高いことが知られていますが、実際に実装する場合を考えたら、Recursive Autoencoder の方が実装コストは少なくて済むでしょう。 Autoencoder は、今回の例のように文だけでなく一般的な次元圧縮器になるので、自然言語処理のみならず幅広く応用することができると考えられます。
詳細のアーキテクチャや説明は、こちらの論文 に詳しく書かれていますので、詳細が気になった方はそちらをご覧ください。
*1:"I saw him swimming." など、連続した単語のピリオドまでのまとまりのこと。
*2:アウトプットは特に重要ではないので捨てちゃうのが普通。
*3:出力はいらないので無視。