代表の島田です。scoutyでは、10/14 と 10/28 に下記の機械学習講習会を行いました。機械学習講習会#1は、このブログで紹介した言語モデルの基礎とNgramによる実践を半日で行うイベントです。
講習会の際に、RNNによる言語モデルについて教えて欲しいといった意見が多く頂きましたので、今回の記事ではRNNによる言語モデルを扱います。
#1(再) scouty 機械学習講習会 〜自然言語処理入門「Pythonでつくる言語モデル」〜
今回は、ニューラルネットワークの拡張型RNNを用いて、ある文が与えられたときその次に来る単語の確率を与える言語モデルを作る過程を紹介します。この記事は、言語モデルに関わらずRNNの一般的な構造を取り扱うので、言語モデル以外にも応用することができます(間違いなどがあればコメントでお知らせください)。
RNNによる言語モデルは、scoutyにおいてもスカウトメールの解析などで使っていこうとしている技術のひとつです。
言語モデルとは
言語モデルとは、クロスエントロピーで名前から国籍判定する - scouty AI LAB の記事でご紹介したように、ある文が(学習元となったデータにおいて)生起する確率を与えるモデルで、例えば、以下のような関係を知ることができます。
$$P(\mathrm{the\ cat\ slept\ peacefully}) > P(\mathrm{slept\ the\ peacefully\ cat})$$
言語モデルがあることで、どの文章がより起こりやすいか=どの文章がより自然か を知ることができるので、機械翻訳や音声認識など応用範囲は様々です。
これを応用すると、ある文 \(x_t, \cdots ,x_1\) (\(x_i\) は文内 \(i\) 番目の単語)が与えられたとき、その次に続く単語として何が続くかを予測することができます。これを数式で表すと以下のようになります:
$$P(x_{t+1} =v_j |x_t, \cdots ,x_1).$$
つまり、言語モデルは ある単語の列 \({x_t, \cdots , x_1}\) が与えられた時の次の単語(あるいは単語の列)\({x_{t+1}}\) が \({v_j}\) である確率を与えます。条件を付さなければ上のように、純粋に文章が生起する確率が得られます。
RNNとは
RNN (Recurrent Neural Network) とは、通常のフィードフォワード型のニューラルネットワークの拡張で、時系列データ(各時間でのスナップショットのシーケンス)や文(単語のシーケンス)のようなシーケンスを扱うことができるようにしたものです。各時刻 \(t\) での隠れ層は、時刻 \(t\) でのインプットに加え、時刻 \(t−1\) の隠れ層を受け取り、両者の和をとります。基本的な構造は以下のようになります:
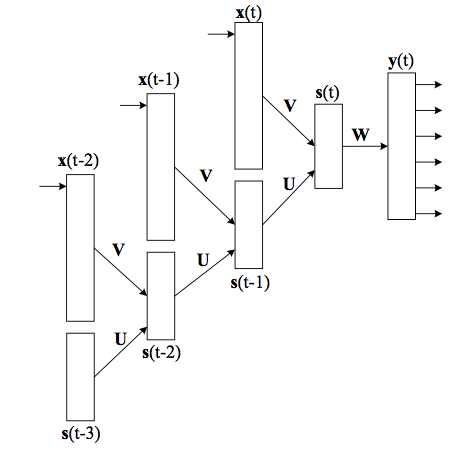
画像は[1]より引用
言語モデルを作る場合、\({\boldsymbol{x}(t)}\) は 文中 \(t\) 番目の単語の one-hot ベクトル*1になります。そして、予測すべきは \(\boldsymbol{x}(t)\) の次に来る単語で、これを \(\boldsymbol{y}(t)\) として吐き出させることで、RNNで言語モデルを構築することができます。
実際に、\(\boldsymbol{s}(t-1)\)の先にも同じように \(\boldsymbol{y}(t-1)\) の出力がついていて、これは \(\boldsymbol{x}(t-1)\) の次に来る単語、つまり \(\boldsymbol{x}(t)\) を予測するという構造になっています。
RNNでも重み行列を学習しますが、通常のNNでの学習と異なるのは3種類の異なる重みの推定を行うという点です。本記事では、3種類の重みを以下のように定義することとします:
- \(\boldsymbol{U}\): 隠れ層 → 隠れ層 の重み
- \(\boldsymbol{V}\): インプット → 隠れ層 の重み
- \(\boldsymbol{W}\): 隠れ層 → 出力 の重み
図中では同じ \(\boldsymbol{U}\) がたくさん現れていますが、これらはすべて同じ行列を表しています。ある単語の次にどの単語が来るかは、単語の絶対的な位置に依存しないので、重み行列は同じであって当然という前提に基づきます。
基本構造:もう少し詳しく
入力 \(\boldsymbol{x}^{(t)}\) に対して、出力 \(\boldsymbol{y}^{(t)}\) を計算する Forward Propagation は次のようになります*2:
$$\begin{align}
\boldsymbol{\mathrm{net}}^{(t)}_{\mathrm{in}} &= \boldsymbol{Vx}^{(t)} + \boldsymbol{Us}^{(t-1)},\\\\
\boldsymbol{s}^{(t)} &= \mathrm{sigmoid}(\boldsymbol{\mathrm{net}}^{(t)}_{\mathrm{in}}),\\\\
\boldsymbol{\mathrm{net}}_{\mathrm{out}}^{(t)} &= \boldsymbol{W}\boldsymbol{s}^{(t)}, \\\\
\boldsymbol{y}^{(t)} &= \mathrm{softmax}(\boldsymbol{\mathrm{net}}^{(t)}_{\mathrm{out}}).
\end{align}$$
これを \(t=0\) から \(t=n−1\) まで順に計算してやればよいわけです。
\(\boldsymbol{y}^{(t)}\) ベクトルは \(t\) 番目の単語の次にくる予測単語の確率を表しています。ある単語のベクトル表現を \(\boldsymbol{w}_j\) とすると、 \(\boldsymbol{w}_j\) は \(j\) 番目の要素が1、他が0のベクトルとなります。 \(\boldsymbol{w}_j\) が \(t+1\) 番目の単語として出現する確率 \(y^t_j\) は次のように表されます:
$$\begin{eqnarray*}
P(\boldsymbol{x}^{(t+1)}=\boldsymbol{w}_j|\boldsymbol{x}^{(t)}, \cdots, \boldsymbol{x}^{(1)}) = y^t_j.
\end{eqnarray*}$$
\(\boldsymbol{x}^{(t)}\) は \(t\) 番目の単語の one-hot ベクトルであるように、 \(\boldsymbol{y}^{(t)}\) は次元数が全単語数のベクトルで、softmax 関数を使っているので全要素の和が1になります。
ボキャブラリーサイズ(全単語数)を \(|V|\), 隠れ層 \(\boldsymbol{s}\) の次元数を \(D_h\)*3 としたとき、各重み行列は以下のような形をとります:
$$\begin{align}
\boldsymbol{U} \in \mathbb{R}^{D_h \times D_h}, \
\boldsymbol{V} \in \mathbb{R}^{D_h \times |V|}, \
\boldsymbol{W} \in \mathbb{R}^{|V| \times D_h}.
\end{align}$$
学習アルゴリズム:BPTT
通常のNNでは Back Propagation (誤差逆伝播法)が学習アルゴリズムに用いられますが、RNNでは Back Propagation Through Time (BPTT) というアルゴリズムが用いられます。基本アイディアは同じで、出力層の誤差を重みを通じて伝播させていきますが、BPTTでは出力層 \(\boldsymbol{y}^{(t)}\) での誤差のみならず、一つの前の時刻 \(t−1\) の誤差を加算するという点が異なります。もちろん、一つだけとは言わず任意のタイムステップ \(\tau\) だけ遡った誤差を加味してもよいでしょう。ただし、 \(\tau\) を大きくすれば当然計算量は増えます。例えば、10ステップ前の誤差まで加味するRNNはレイヤー数の10の FeedFoward NN の計算量に匹敵するので、適切な \(\tau\) を設定する必要があります(これもまたハイパーパラメータ)。遡るタイムステップ数 \(\tau\) を限定したBPTTを Truncated BPTT といいます。また、多層NNと同じ理由で Vanishing Gradient Problem も発生します*4。
以下が、各重みの更新式となります。添字 \(p\) は、データ内から取ってきたセンテンス \(p\) を表します。\(\boldsymbol{x}_p^{(t)}\) は \(p\) 内の \(t\) 番目の単語です。\(\boldsymbol{d}_p^{(t)}\) は教師データ (desired vector)、つまり、\(\boldsymbol{x}_p^{(t)}\) の次に実際に来る単語です。通常、\(\boldsymbol{d}_p^{(t)} = \boldsymbol{x}_p^{(t+1)}\) となります。
$$\begin{align}
\boldsymbol{\delta}_{\mathrm{out},\ p}^{(t)} &= (\boldsymbol{d}_p^{(t)} - \boldsymbol{y}_p^{(t)})g'(\boldsymbol{\mathrm{net}}_{\mathrm{out},\ p}^{(t)})\\
\Delta\boldsymbol{W}_p^{(t)} &= \boldsymbol{\delta}_{\mathrm{out},\ p}^{(t)}\ \boldsymbol{s}_p^{(t)} \\
\end{align}$$
\(\boldsymbol{W}\) は純粋にアウトプットのエラー(\(\boldsymbol{d}_p^{(t)}\) と \(\boldsymbol{y}_p^{(t)}\) の差)だけに影響を受けるので、タイムステップを遡る必要はありません。
$$\begin{align}
\boldsymbol{\delta}_{\mathrm{in},\ p}^{(t-k)} &= \begin{cases}
\boldsymbol{W}^T\boldsymbol{\delta}_{\mathrm{out},\ p}^{(t)}\ f'(\boldsymbol{\mathrm{net}}_{\mathrm{in},\ p}^{(t)}) & (k=0) \\
\boldsymbol{U}^T\boldsymbol{\delta}_{\mathrm{in},\ p}^{(t-k+1)} f'(\boldsymbol{\mathrm{net}}_{\mathrm{in},\ p}^{(t-k)}) & (k>0)
\end{cases}\\
\Delta\boldsymbol{V}_p^{(t-k)} &= \boldsymbol{\delta}_{\mathrm{in},\ p}^{(t-k)} \otimes \boldsymbol{x}_p^{(t-k)}\\
\Delta\boldsymbol{U}_p^{(t-k)} &= \boldsymbol{\delta}_{\mathrm{in},\ p}^{(t-k)} \otimes \boldsymbol{s}_p^{({t-k}-1)}
\end{align}$$
なお、\(\otimes\)は直積 (outer product) を表します。
今回は損失関数に Cross Entropy Loss を使用し、活性化関数に sigmoid と softmax を利用しているので、それらの微分は次のようになります:
$$\begin{align}
g'(\boldsymbol{\mathrm{net}}_{\mathrm{out},\ p}^{(t)}) &= \boldsymbol{I},\\
f'(\boldsymbol{\mathrm{net}}_{\mathrm{in},\ p}^{(t)}) &= \boldsymbol{s}_p^{(t)} ( \boldsymbol{I} - \boldsymbol{s}_p^{(t)}).
\end{align}$$
\(\boldsymbol{I}\) は成分がすべて1である適当な長さのベクトルです。なお、断りがない限りベクトルどうしの積は対応要素ごとの積を並べたベクトルとします。
これを遡るタイムステップ \(\tau\) ぶんと、全データ \(N\) について足し合わせればよいというわけです。つまり、重みの更新式は以下のようになります:
$$\boldsymbol{W} \leftarrow \boldsymbol{W} + \eta \sum_{p}^{N} \sum_{t=1}^{n} \Delta\boldsymbol{W}p^{(t)}.$$
ネットワークの形は異なりますが、学習や順伝播など、基本的なアイディアはほとんど通常のニューラルネットワークと同じですね。
希望が多ければ、次回の scouty 機械学習講習会イベントのテーマにすることも検討しています。
参考文献
[1] Guo, Jiang. "Backpropagation through time." Unpubl. ms., Harbin Institute of Technology, 2013.
https://pdfs.semanticscholar.org/c77f/7264096cc9555cd0533c0dc28e909f9977f2.pdf
[2] Frank Keller, Natural Language Understanding - Lecture 11 Recurrent Neural Network, University of Edinburgh, 2016.
*1:次元数=全単語数で、そのベクトルが表現する単語の成分だけ1,他が0になっているベクトル。
*2:t に関する表記法が [1] とやや異なりますが、本記事の以降の部分はこちらのノーテーションに従うこととします。
*3:Dhは自由に決められるハイパーパラメータの一つです。
*4:その解決策がいわゆるLSTMです。