scouty代表の島田です。
「競合優位性に関わる技術でない限り技術情報をオープンにしていく」というポリシーのもと、今回は、scoutyのサービス内で実際に使われている、「名前の文字列からその人の国籍を判定する」というアルゴリズムを紹介します。
初回ということもあり、非技術者の方にもわかりやすくscoutyで使っている技術をご紹介したいと思います。
アルゴリズム概要
平たく言うと、今回ご紹介するのはアルファベットで表記された名前の文字列を受け取って、その名前の人物の国籍を推定するというアルゴリズムです。下記のように動作します。
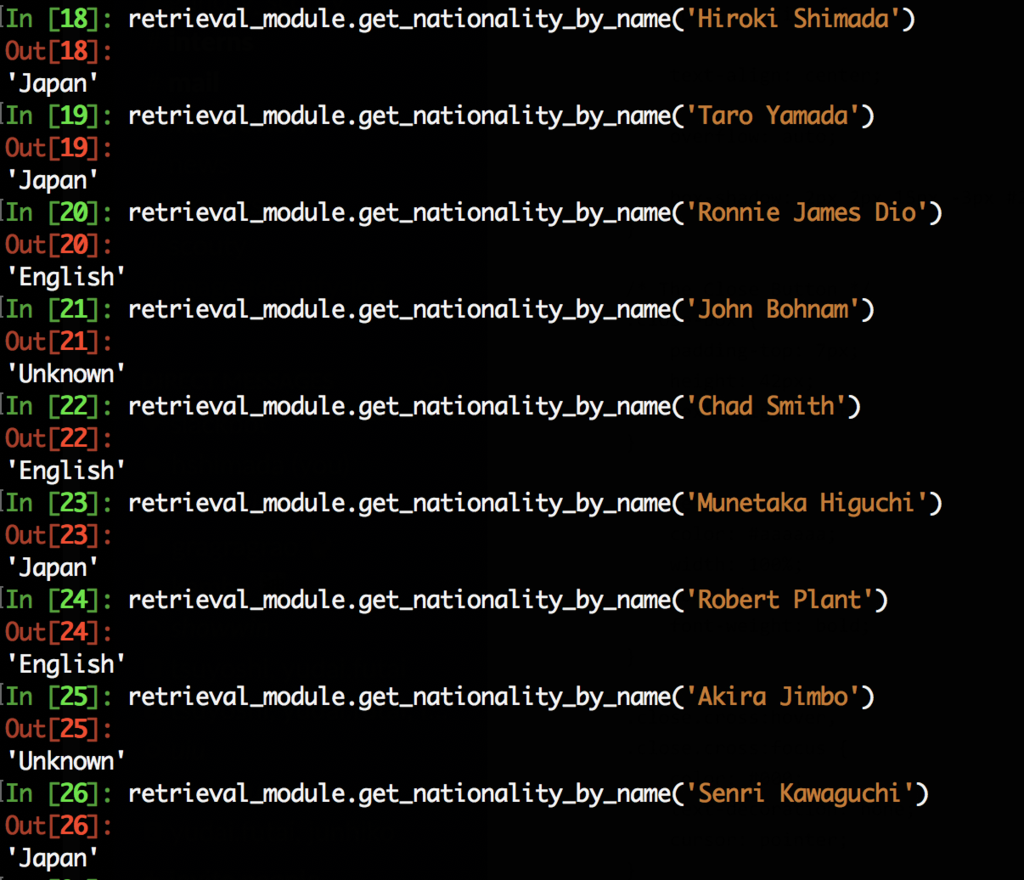
上記の例は英語圏の名前か(English)日本の名前(Japan)かを判定しています。実際のモジュールでは非英語圏(ロシア語など)やマルチバイトの名前(漢字で表記されていた場合の、中国人 / 日本人 判定)も判定できますが、今回は割愛します。
サービス上では 誤判定に高いペナルティを与えている という理由で、自信が無ければ "Unknown" と表示される仕様になっています。「Bohnam」のような珍しい名前には "Unknown"が返されています。
ネット上に自分の国籍(人間にとっては自明だったりするので)をアップしている人は多くはありません。scoutyはオープンデータから情報を取っているという性質上、scoutyサービスでは国籍を自動的に予測しなければ膨大なデータから日本人をフィルタリングすることはできません。この技術は下記のような検索時に実際に使われています。
基本原理
ズバリ、このアルゴリズムの基本原理は 「各国籍の名前の集合をひとつの言語 と見立てその言語モデルを作り、そのモデルで与えられた名前の生起確率を計算し、それをもとに判定を行なう」というものです。
言語モデルとは?
自然言語処理(NLP) の基礎を復習しましょう。言語モデルとは、「その言語において与えられた単語や文(章)が発生する確率を与えてくれるもの」です。たとえば、"This is a pen." と "This is pen."という文章なら、前者の方が発生確率が大きいはずです(後者は文法のミスがあるので)。これは
$$P(This\ is\ a\ pen) > P(This\ is\ pen)$$
と表せます。この確率を与えてくれるのが言語モデルで、上の例のように言語モデルは文法チェックやスペルチェックに使われます。
1つの文の生起確率は、下記のように分解して考えることができます。
$$P(this\ is\ a\ pen) = P(this | \mathrm{head}) × P(is|this) × P(a|is) × P(pen| a)$$
\(P(is|this)\) は "this"のあとに"is"が続く確率を表していて、これらをすべて掛け合わせることで、その文の生起確率が計算できます。(この例は直前1単語を見ていますが、直前 \(n\) 単語を見ることで精度を上げることも出来ます)
※ \(\mathrm{head}\) は文頭を表す。
名前の例
上記を名前に応用してみます。
下記、\(P_e\) は英語の名前でつくった言語モデルです。つまり、英語の名前で起こりやすい文字列に対して、高い確率を返します。この場合、"Andy" という名前の起こる確率は
$$P_e(Andy) = P_e(A|\mathrm{head}) × P_e(n|A) × P_e(d|n) × P_e(y|d)$$
と表せます。 この例からわかるように、ひとつの名前の生起確率は、それを構成している各文字の連続の生起確率によって表されます。
ここで、日本語名の言語モデルを \(P_j\) とすれば、
$$P_e(y|d) > P_j(y|d)$$
となります。なぜなら日本語の名前では "d"のあとに"y"が続く名前なんて極めてレア(というか存在しないのでは?)なのに対し、英語では "Andy" やら "Sindy" やらいろいろあるからです。
実際に作ってみる
どうやって言語モデルを作るか?
この言語モデルをどう作るかというと、極めてシンプルで、ただ教師データの中に出てきたサンプル数の数で割り算をするだけです。
これは言語モデルを作る上で最も単純なNgramというやり方ですが、例えば上の例で出た\(P(y|d)\) は単純に下のように求められます。
$$\displaystyle
P(y|d) = \frac{C(dy)}{C(d)}$$
\(C(dy)\)、\(C(d)\) はそれぞれ、学習データの中で "dy"が現れた数、"d"が現れた数です。(実際は分母や分子が0の場合を考えてSmoothingという処理をかける必要がありますが、割愛)
このようにしてすべての2文字の組み合わせについてこの確率を計算し、保存したものが言語モデルにほかなりません。(組み合わせが膨大なので、学習には時間がかかります。)
実際、Ngram以外にも言語モデルを作るやり方はたくさんあります。
(RNNというDeepLearning のアーキテクチャを使って作るやり方を今後紹介したいと思います)
教師データ
上記の\(C(dy)\) や \(C(d)\) などのような数字を得るため、日本人の名前を大量に集めたデータと、英語圏の人の名前を大量に集めたデータが必要になります。
scoutyは、オープンデータから情報を取得しているので、そこに蓄積した情報を使って教師データを作成しました。
国籍を公開している人は少ないですが、SNS上に各人が公開しているLocation情報を使って、「日本にいる人の名前集合」「英語圏にいる人の名前集合」を作成しました。
これは厳密には国籍ではない(日本在住の外国人もいるかもしれない)ですが、データ量を増やすことでそういったノイズを軽減し、近似することができます。
今回は、英語圏と日本合わせて約8万件のデータを使って学習しました。
クロスエントロピー
言語モデルはただの生起確率を表しますが、もう少し良い指標があります。それがエントロピーです。
文字列\(\boldsymbol{X}\)のエントロピー\(H(\boldsymbol{X})\)は一般に、
$$\displaystyle
H(\boldsymbol{X}) = - \sum_x -P(x)\log_2{P(x)}$$
と表されます。数式は直感的でないですが、エントロピーは不確かさの尺度を表します。エントロピーを利用したほうが計算がしやすくなります。
また、もうひとつの問題として、上の計算方法では単純に単語が長くなればなるほど、確率(少数 < 1)の掛け算が続くので、生起確率は小さくなります(エントロピーは大きくなります)。
それでは本質的ではないので、これを名前全体の文字数でならした指標を使います(※定義ではありません)。それがクロスエントロピーです。クロスエントロピーはもちろん、言語モデルによって変わります。
$$\displaystyle
H(w_1, \cdots, w_n) = - \frac{1}{n}\log_2{P(w_1, \cdots, w_n)}$$
\(wi\) は、名前中の\(i\)番目の文字にあたります。
つまり、言語モデルAでのクロスエントロピーが大きいほど、その名前がその言語Aで起こりにくいことを示します。
従って、クロスエントロピーがある一定のしきい値より低いかどうかで、その名前がその国籍かどうかを判定します。(あるいは、複数のモデルでエントロピーを計算して、その値が最も小さいモデルの国籍だと判定することもできます。)
実装方針
今回の記事ではコードを公開することは趣旨とは異なるので、簡単に実装方針に触れるだけに留めておきます。
PythonではNLTK(Natural Language Tool Kit)という自然言語処理ライブラリがあり、この NgramModel というクラスを使うことで、比較的簡単にNgramによる言語モデルを実装することができます。 entropyというメソッドを使って言語モデルに対してクロスエントロピーを計算することもできます。
まずは日本人の名前で言語モデルを作成し、エントロピーの閾値を設定してそれ以下なら日本人、それ以外なら外国人と定めます。
閾値は、サービスの誤判定に対する許容度に応じて、ヒューリスティックに設定します。低ければ低いほど精度は上がりますが(Precisionは上がるがRecallは下がる)Unknownと判定されることが多くなります。
さらに、英語圏の人の名前でモデルを作り、同様に計算することで判定アルゴリズムを作ります。
複数のモデルの結果を使って、判定器を作ります。
実際に使ってみる
精度
上記のアルゴリズムの精度を検証してみます。
日本にいる人1000件とアメリカ・イギリスにいる人1000件のデータ2000件でテストした結果です(データに偏りをなくすため同一数でサンプリング)。
教師データは、モデルを作った手法と同じように、Locationで作成している上、テストデータにはニックネームも多く含まれているので、あくまで参考程度の値となります。
正:756(うち日本人と判断されたのが385、英語圏と判断されたのが371)
Unkwnon:1220
誤:24
Precision:96.9%
Recall:37.8%
F:0.537
サービスとしてPrecision(適合率)の方が重視されているので、閾値を厳し目にして、わからないものはUnknownに判断するような仕組みにしています。
※ Recall, Precision, F値に関してはこちら:F値 - 機械学習の「朱鷺の杜Wiki」
※ 実際のサービスでは 名前以外の情報からも国籍を判定しているので、実際の精度はこの値よりも高くなります。
これからやろうとしていること
scoutyでは、今回の記事で紹介したこと以外にも、今後以下のようなことにチャレンジしていきます。
- Recallの改善
- 今回は 2gram (前後2文字のつながりを見る) のみのモデルを作ったが、3gram, 4gram などの別なモデルとの精度を比較すること。場合によっては違うモデルを複合させたほうが精度が出るかも。
- N-gram以外の手法(RNNなど)で言語モデルを構築し、本手法と比較すること。
- 別モデルで学習して、ニックネームと本名の判別のほか、
- 女性の名前では ko や mi や e で終わる名前が多いといった特徴があるので、同じ原理を使えば、日本人の名前から性別推定も可能。
- 名前だけではなく、投稿の言語や投稿のロケーションにより国籍を特定すること。
言語モデルとエントロピーを使う方法は、手法としては新しくはないですが、学習モデルを変えることによりいろいろなことに応用ができるので、実用では非常に有用です。
scouty AI LABでは、このようなことを継続的に行って、競合優位性に関わる技術でない限りオープンにしていこうと考えています。
また、scoutyでは上記のような技術課題にチャレンジしたいという機械学習エンジニアを募集しています。
我こそは!という方は、こちら からご連絡ください。単なるディスカッションでも歓迎です!