はじめに
こんにちは、LAPRASのAILABチームです。今回は池・田嶋・森元で、LAPRASポートフォリオのタグをエンジニア関連のタグ(エンジニアタグ)とそうでないタグ(非エンジニアタグ)に分類する分類器を検討してみました。ここではその実験の詳細と、また再現性のある方法で分類器を得るためのパイプラインについて検討した内容をまとめます。
タグ分類
現在のLAPRASポートフォリオ上では図のようにユーザーのアウトプットから抽出したタグが表示されています。

このタグは現在カテゴリ分類されておらず、ユーザーの技術力を表すものであるのかがわかりづらくなっています。そこで私たちはタグのカテゴリ分類を行うことを検討しました。ポートフォリオ上での出し分けや、今後のMatching Intelligenceでの人×求人のマッチング時への応用などを考えて、今回はエンジニア関連のタグ(エンジニアタグ)とそうでないタグ(非エンジニアタグ)を明示的に分類する実験を行いました。
パイプライン
一般に、機械学習におけるパイプラインとは、データの収集や前処理、モデルの学習、評価、デプロイまでをend to endで実施できる仕組みのことを指します。一人で単一のJupyter Notebookでこれらを一個一個実施する代わりにパイプラインを用意することで、チームのスケーラビリティと再現性の担保を目指します。[1]
今回行うタグのカテゴリ分類において、タグは日々LAPRASのクローラによって新しいものが生成されています。そのため、いつでも再現性を保ったやり方で最新の分類器が手に入る仕組みが必要となります。
例えば今から1年後に、現時点では想像できないような単語が世のエンジニアの間で一般的に用いられるようになったとしても、その単語のタグをエンジニア関連のタグと分類できる分類器が簡単に手に入るように、パイプラインの作成を検討しました。
ただし、今回は具体的なパイプラインの実装には至っておらず、論理的な設計までを行いました。今後この設計を基に、自前でのパイプラインの構築やSageMakerなどのマネージドサービス上でのデプロイなどを検討する予定です。
アプローチ
今回のタグ分類において以下のようなパイプライン作成を考えています。
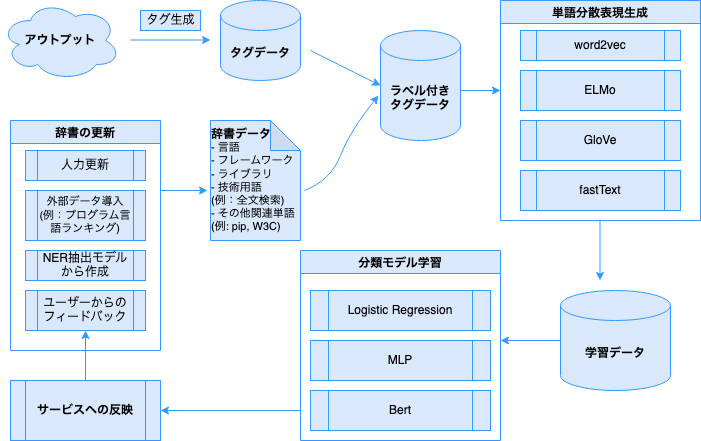
今回のパイプラインの特徴としては、モデル構築において常に最新なデータに対応したモデル更新のためのサイクル性・多様な選択肢・学習データのタグ辞書からの自動生成が挙げられます。
サイクル性:
本番環境からのフィードバック情報を自動的に収集し、タグ辞書を更新することで、継続的なモデル更新が可能になります。
多様な選択肢:
将来の未知のデータに対応できるように、単語分散表現と分類モデル学習で複数の手法から選択できる余地を残しています。
学習データ自動生成:
新規技術や予想できなかった関連用語のような既存タグ辞書にないタグが自動的に追加されることにより、常に最新の学習データが生成可能になります。
以下にパイプラインのそれぞれの処理ついて詳細を記述します。
タグデータ
LAPRASではGitHubのリポジトリの説明文やブログ記事の内容などの文章からタグを生成しており、2021/06/10 時点でLAPRASのデータベースには 1,877,070 個のタグが存在します。各タグはそのタグを用いている人数の情報を持っています。
今回は、なるべく一般的なタグの分類をしたかったので、用いている人数が 200 以上のタグ、つまり全体の 0.01% 以上の人が用いているタグ 14,363 個を学習データとして利用します。
ラベル付きタグデータ
タグ辞書(エンジニアタグを集めたタグリスト)を参照しながらエンジニアタグのラベルをつけます。
ラベリングの正解データとなるタグ辞書の作成についてですが、DB Pediaを用いてカテゴリがプログラミング言語・フレームワークなどエンジニア技術を表しているカテゴリに含まれる単語 665 個を抽出して作成しています。
今回はタグの表記揺れに対応できるように、タグデータとタグ辞書両方に対して、小文字化、スペース削除、編集距離による正規化を行なった結果を比較し、正解ラベルを付与します。
特徴量生成
特徴量としてタグレベル、出現頻度などいろいろ考えられますが、このパイプラインでは単語分散表現を扱うことにします。
今回、タグの単語分散表現は日本語Wikipedia本文全文から事前学習したword2vecモデルを用います。上記のようにタグやタグ辞書に対して正規化を行っているにもかかわらず表記揺れ、表記ミス、スペルミスなどが原因でword2vecモデルからベクトル表現が取得できない可能性があり、今回の場合実質タグの 67 %、タグ辞書の 25 %しか単語分散表現への変換ができませんでした。
学習データ
今回はタグ辞書の参照と分散表現への変換を経て最終的に 122 件の正解をもつ学習データを生成しました。
| データ名 | サイズ |
|---|---|
| タグ | 14,363 |
| タグ辞書 | 536 |
| 正規化、ベクトル化後のエンジニアタグ | 122 |
| 正規化、ベクトル化後の非エンジニアタグ | 9,500 |
分類モデル学習
分類モデル学習ではLogistic Regression, MLP, Bert, GCNなどいろんなモデルを格納し、データ量、データ特徴によって最適のモデル学習を行うことをめざします。
分類モデルとして、今回は 200 次元のタグの単語分散表現をinputとする単純な3層パーセプトロンを使います。
サービスへの反映
全自動のパイプラインを考える上で、
- デプロイまでワンストップでやりたい
- 機械学習エンジニアとシステムエンジニア間の協業をスムーズに行いたい
という観点から将来的にはAmazon SageMakerを使って、定期的にモデル更新を行うことを目指します。
タグ辞書の更新
タグ辞書更新はパイプラインのサイクル性を担保するための重要なステップになります。このステップが完成されることにより、継続的なモデル更新が可能になるわけです。
タグ辞書更新の手法として、人力更新、外部データ導入による更新、自前NER抽出モデルによる更新、さらにサービス上ユーザーからのフィードバックによる更新などが考えられます。
今回はこちらの検証までは至らなかったですが「サービス上ユーザーからのフィードバック」についてはLAPRASポートフォリオ上に分類表示されたタグに対してユーザーがアノテーションできる機能とか考えられます。
実験結果
今回は上記アプローチに従ってまず分類モデル学習までを行い、単語分散表現を使ったタグ分類が実現可能そうかを確認しました。
| 評価軸 | 評価値 |
|---|---|
| accuracy | 0.50 |
| precision | 0.38 |
| recall | 0.83 |
| f1 | 0.53 |
混同行列
| 非エンジニアタグ(予測) | エンジニアタグ(予測) | |
|---|---|---|
| 非エンジニアタグ(正解) | 17 | 32 |
| エンジニアタグ(正解) | 4 | 20 |
ROC曲線
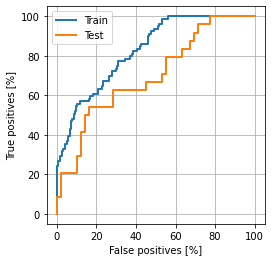
AUC = 0.69
実験の結果、いずれの指標を見ても分類がうまくいかず「ランダム分類よりはちょっと良い」ぐらいの精度でした。よって、モデル精度向上を目標に分類精度が上がらない理由について調べました。
結果の確認
分類結果を人手で確認したところ、タグ辞書にはないが明らかにエンジニアタグであるもので、且つ分類器が正しく分類できているものが見られました。私たちの用いたタグ辞書は、前述のようにプログラミング言語・フレームワークのみを利用したタグ辞書であり、これは厳密には私たちの求めたいエンジニアを表すタグ辞書にはなっていませんでした。よって私たちはアップデートが必要であると判断して、明らかにエンジニア関連であるタグをタグ辞書に追加しました。
人手で見て明らかにエンジニアタグであるとしてタグ辞書に追加したタグの例は以下です。
コンパイラ、全文検索、ORM、kernel、レポジトリ、プロンプト、W3Cタグ辞書を増やした後の結果
タグ辞書を増やした後の結果は以下のようになりました。
| 評価軸 | 評価値 |
|---|---|
| accuracy | 0.69 |
| precision | 0.52 |
| recall | 0.88 |
| f1 | 0.65 |
混同行列
| 非エンジニアタグ(予測) | エンジニアタグ(予測) | |
|---|---|---|
| 非エンジニアタグ(正解) | 49 | 33 |
| エンジニアタグ(正解) | 5 | 36 |
ROC曲線
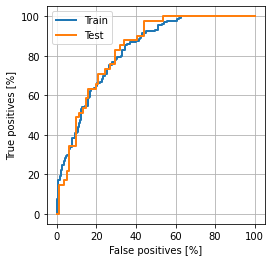
AUC = 0.83
タグ辞書拡張を経て再モデリングを行った結果、明かな精度向上がみられました。AUCが 0.69 から 0.83 に上がり、学習データとテストデータ間の乖離も少なく、よりデータの分類を再現したモデルができているように見えました。
ただ、この結果だけでは両モデルの学習、評価データの違いから投入データへの再現はうまくできていると言える一方で、汎用性の面で本当に良いモデルであるのかどうか言い難いと思います。さらに、分類結果がタグ辞書データに偏っているのではないかという懸念も残っています。
よって、厳密ではありませんが、今回はモデリングで使っていないデータに対して分類を行い、タグ辞書拡張前後モデルがどんな分類を行っているのかを確認しました。
未学習データで分類を行った結果
未学習タグ 8,293 件に対して、タグ辞書拡張前後モデルそれぞれで分類を行いました。結果、両モデルともにタグ辞書にはないエンジニアタグを予測していることがわかりました。
例えば、IT企業名(e.x. NEC)、プログラミング言語(e.x. アセンブリ言語、VBS)、オペレーティングシステム(e.x. OpenBSD)などなんとなくエンジニアと関わりのありそうな単語がエンジニアタグとして予測されていました。このことから単純なタグ辞書ベースのタグ分類よりタグ辞書拡張後でのモデルの方が汎用性のある分類ができていることがわかりました。
結果としてタグ辞書の単語を増やした場合、より精度が上がる結果となりました。このことからより網羅性の高いタグ辞書を作成することができたと言うことができそうです。
おわりに
今回私たちは、LAPRASのポートフォリオに表示しているタグについて、エンジニアタグと非エンジニアタグに分類する分類器と、この分類器の再現性を担保したやり方で手に入れるためのパイプラインを検討しました。
分類器では、当初用いていたタグ辞書をベースに作成した学習データでは期待する精度が得られなかったため、私たちの主観に基いて拡張したタグ辞書を新たに開発し、これをベースとした学習データで同一のモデルを評価したところ精度が向上することを確認できました。
今後の課題として、今回は主観に基いてタグ辞書を拡張しているため再現性が乏しいという点があげられます。今後、タグ辞書を拡張する際の客観的な基準を作ることで、分類器の精度向上につなげていきたいと思います。
パイプラインについて、具体的な実装には至っていませんが、「タグ辞書拡張が精度向上に繋がっている」という事実からパイプラインの有効性が検証されたかと思います。こちらは今後実際にこれを構築して、将来にわたり任意のタイミングで最新の分類器を得られるようにしていきたいと思います。
最後にタグ分類の今後の応用についてですが、上述した課題を解決した上で、実際にLAPRASのポートフォリオ上でエンジニアタグと非エンジニアタグを視覚的に区別できる形での表示や、Matching Intelligenceでの人×求人マッチングへの応用へと繋げていきたいと考えています。
参考文献
[1] Valliappa Lakshmanan, Sara Robinson, Michael Munn (2020). Machine Learning Design Patterns. O'Reilly Media, Inc. 282.