scouty代表の島田です。 今回の記事は、2017年9月21日に scouty ✕ talentio ✕ eureka で行われた下記の 「Ventures Engineer MeetUp #02 - AI & Server Side」というイベントで発表した「アルゴリズムマネジメント&デザイン 〜機械学習の技術選定とマネジメントについて〜」という発表を記事化したものです。(当日は、自分が突如入院してしまったのでリードエンジニアの showwinに代理登壇してもらいました)
今回は、scoutyで実際にAIを用いたアルゴリズム開発を例に、「AIビジネスを成功に導くにはどうすればよいか」という問の下、アルゴリズムのプロダクトマーケットフィットの確認のほか、事前リサーチやアルゴリズムの仕様決定や技術選定を行なう「アルゴリズムマネージャ」という役割とその必要性について説明します。 画像は、主にイベントのスライドから抜粋したものになります。
本記事でのAIの定義
本記事でいうAIおよび人工知能という言葉は、人工知能分野に含まれる研究や技術のことを指します。次の図(ML, DM, and AI Conference Map より引用)における Artificial Intelligence をはじめ、 Artificial Intelligence の領域と接している Computer Vision や NLP、Data Mining、Machine Learning などの分野を含む広い領域がこれに該当します。
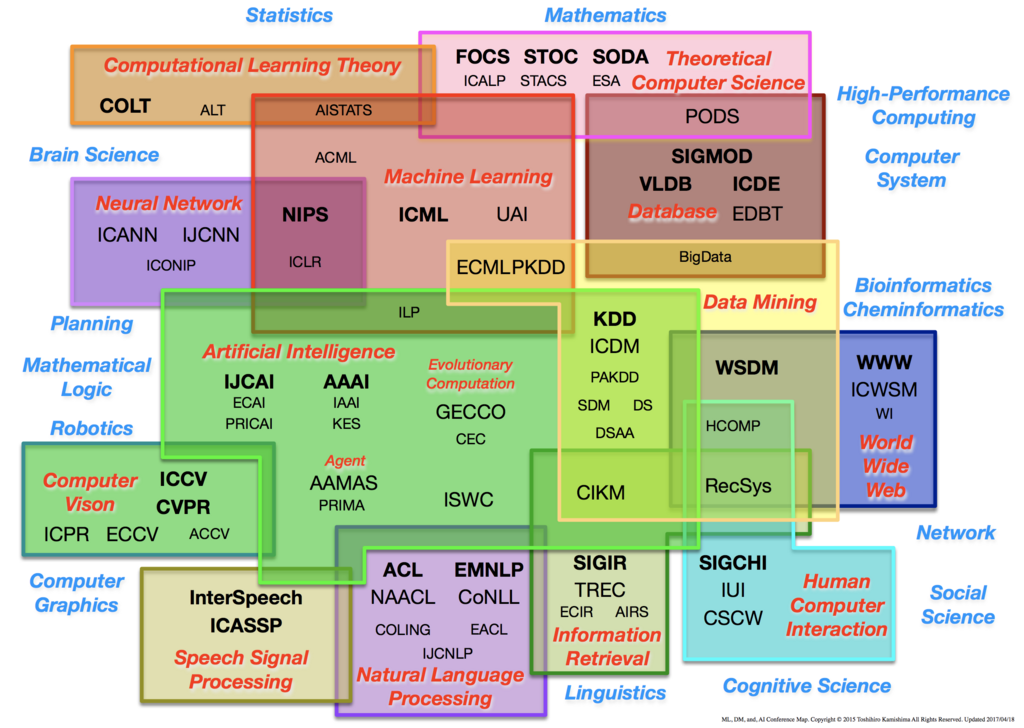
AIビジネスというのは、事業のコア課題の解決の手法として上記でいうAIを利用しているビジネスのことを指します。
何故アルゴリズムマネージャが必要か
まず、本題に入る前に伝えたいことは、AI分野の研究とAIビジネスは全く別物だということです。 AI分野の中でも特に機械学習分野の研究では、一般に新しい手法を使って既存手法よりも高い数値を叩き出すことが大きな目標となっています。 そのためエンジニアとしては、少し精度を改善しただけで悦に浸りたくなります(実際、こういった瞬間はとても嬉しいものです):

しかし、ビジネスの世界では精度の向上が必ずしも事業上のKGIの向上に繋がるとは限りません。
また、実際、上のようなタイプのエンジニアよりも、現実として見かけるのは次のようなエンジニアです:

自分もエンジニアなのでよくわかりますが、エンジニアはHOWにこだわる生き物です。問題をどうスマートに、どうエレガントに(そして時には派手な手法を使って)解決することができるかに関心を払います。つまり、手法にこだわります。しかし、研究(あるいは趣味)と ビジネスの最大の違いは、顧客がいることです。 ルールベース(人工無能)だろうが人工知能だろうが、顧客の課題を解決できなければビジネスでは意味が無いのです。
つまり、エンジニアに丸投げしても、良いAIビジネスは生まれません。おそらく、この業界で蔓延しているひとつの大きな誤解は、「優秀な機械学習エンジニアがいればAIビジネスはうまくいく」という考え方でしょう。
それでは、ビジネスを一番良くわかっているCEOに聞いてみましょう:

やはりダメでした。以前より「何でもかんでもディープラーニングを使えばいいわけじゃない」という考え方は浸透してきたものの、依然としてこれに近いことを言っている経営者やマネージャは多いものです。つまり、良いAIビジネスを作るためには、技術とビジネスの間に立つ人が必要なのです。
では、正しい問いはどのようなものになるのでしょうか。おそらく、それは次のようなものです:

つまり、アルゴリズムがプロダクトマーケットフィットしているか(つまり、顧客が求めているか)を検証することがもっとも重要なのです。これを行なう人を、scoutyではアルゴリズムマネージャと呼んでいます。アルゴリズムマネージャはいわばアルゴリズムのプロダクトマネージャです。一般的なCTOの仕事とは守備範囲が異なりますが、多くの組織ではCTOが似たような役割を兼任していることが多いでしょう。 「顧客が必要としているの?」と問うこと自体はたとえ非技術者でもセンスがあればCEOでもできることですが、アルゴリズムを実際に顧客が必要とするものにすることは、技術的知識が無いとできません。次のセクションで、実際にアルゴリズムマネージャどんな仕事をするのか見てみましょう。
アルゴリズムマネージャの仕事
scoutyは、2017年11月8日に転職可能性予測アルゴリズムのβ版を発表しました。
この転職可能性予測アルゴリズムの開発を例にとり、アルゴリズムマネージャの実際の仕事を次の各項目に整理しました。
- システムダイナミクスマップの構築
- メトリクス定義と評価
- ロードマップ構築
- 事前リサーチ
- 技術選定
- オペレーションの設計
各項目で用いられている図は、説明用に作成されたものなので、実際のアルゴリズム開発で用いられたものとは異なります。
システムダイナミクスマップの構築
システムダイナミクスマップは、「アルゴリズムの精度が1%上がると、ビジネスKGIがどのくらい伸びるのか?」ということを規定します。図中では、ビジネスKGIとKPI、アルゴリズムのメトリクスを抜き出し、正の因果関係がある要素ごとに矢印を張り、それぞれの強度を矢印の太さで表しています。scoutyの転職可能性予測(退職率予測)アルゴリズムでの例は次のようになります。
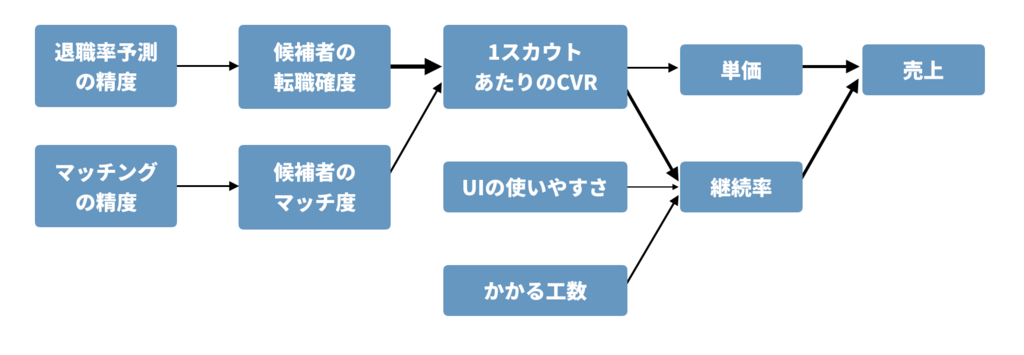
このマップを描く際のコツは、マップを右(ゴール)から描くということです。売上を最大化しようとした結果実は機械学習がいらなかった、ということもあるので、ビジネス成果にこだわるのであればソリューションドリブン(解決策・アルゴリズムから考える)なやり方よりも、課題やゴールから出発したほうが有効でしょう。 このマップを正確に持つために、アルゴリズムマネージャは日々顧客のところに行ったり、現場の人と喋ったり、開発以外のことをしなければいけません。
メトリクス定義と評価
アルゴリズムは、改善のPDCAを回すにあたって評価することが必須になります。そこで、評価の指標となるメトリクスを定義します。 メトリクスは一般にアルゴリズムの精度に近いものをとりますが、一口に精度といっても、Precision、Recall、F値、平均二乗誤差などいろいろな指標があるので、そのどれを使って評価を行なうかを定義します。次の画像は、scoutyの転職可能性予測(退職率予測)アルゴリズムにおける評価軸の一例です。
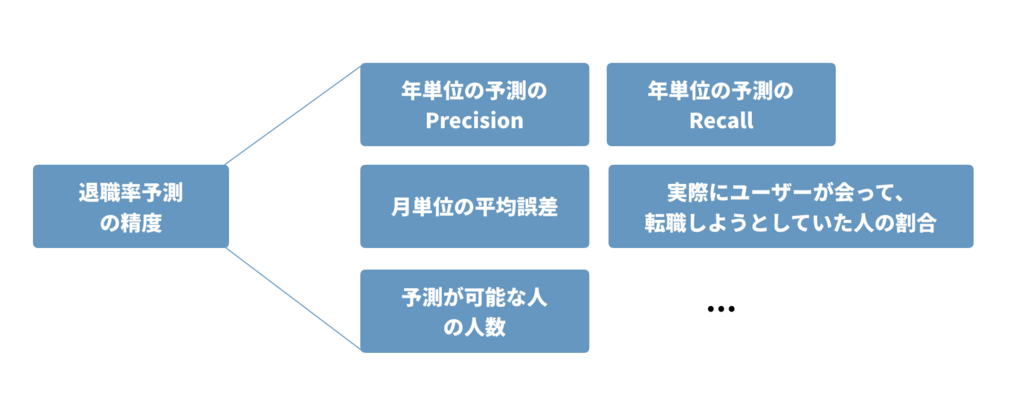
その数値が上がると、必ずKGIが上がり、 かつ測定しやすいもの をメトリクスとして定めると良いでしょう。しっかりとマップを見ながらKGIに結びつくものを決定します。
ロードマップ構築
最初から完璧なversion1はありません。最初から完璧なものを作るよりも、どのようなマイルストーンをどういうスケジュールで達成していくかというロードマップを構築することが重要となります。 例えば、次のようなスケジューリングが考えられます:
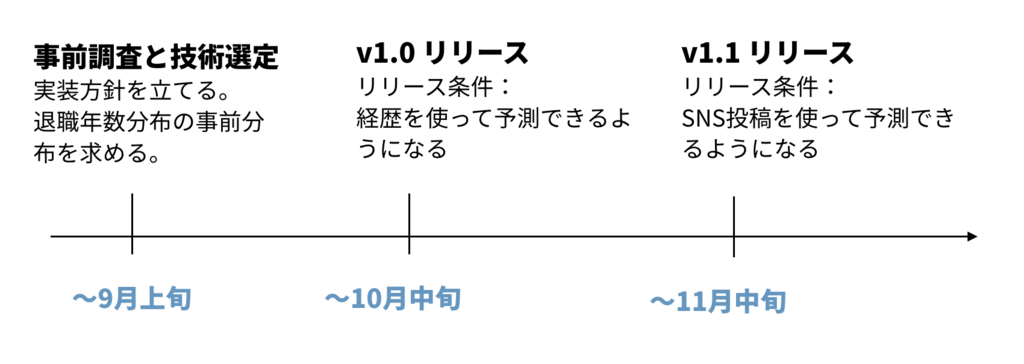
これは短期的なスケジュールの例ですが、次にどのような条件が揃えば次のバージョンがリリースできるのか等、長期的なロードマップを作ることも重要です。 scoutyでは、「ルールベースレベル」「ライブラリ適用レベル」「最先端技術適用レベル」のような形で各アルゴリズムをレベル分けし、それぞれがどのフェーズにいるかを確認できるシートを作っています。フェーズごとに求められるエンジニアや技術の種類が全く異なるので、アルゴリズムがどのフェーズにいるかを常に把握しておく必要があります。
ロードマップやスケジュールに精度を含めるかに関しては、議論の余地があります。精度を含めても、単純に機械学習系のタスクは「〜〜をすると◯%上がる」といった単純な世界ではないので、結局設定した精度に達しない(そのための施策もわからない)、ということになり無意味なスケジュールとなってしまいます。「ビジネス上◯%までいかないと使えないから、◯%までいかなければ開発を辞める / リリースをしない」といった判断は可能かもしれませんが、「△ヶ月後に◯%まで伸ばす」というスケジュールはナンセンスなものになりがちです。したがって、「いつまでに◯◯を行なう」という施策ベースでスケジュールを立てるほうが現実的かもしれません。
事前リサーチ
事前リサーチをすることで、アルゴリズム開発の後工程が数倍楽になります。 事前リサーチをする主な目的は、「仮説を事前検証することで実装工数を減らすこと」と言って良いでしょう。実際のアルゴリズムを実装しながら、「あれも効果ない、これも効果ない」などとやっていては、工数がかさみます。
scoutyは、Jupyter Notebookで雑でもいいので特徴量ごとに転職年数分布の有意差が出そうかを実験してまとめていました。実際にリサーチを行ってまとめる人はアルゴリズムマネージャでなくても構いません(scoutyでもリサーチ業務はインターンが担当)が、リサーチ項目を決めたり仮設を立てたりする部分はアルゴリズムマネージャが率先してやるべきでしょう。 転職可能性予測アルゴリズムでは、「使用プログラミング言語ごとに勤務年数分布が変わるんじゃないか?」という仮説が出たので、実際のアルゴリズムに組み込む前に雑に集計を採りプロットをしました。結果、グラフは以下のようになり(横軸が勤務年数、縦軸が割合)、大きな差が無いことが確認できたので、アルゴリズムに取り込むことは止めました。
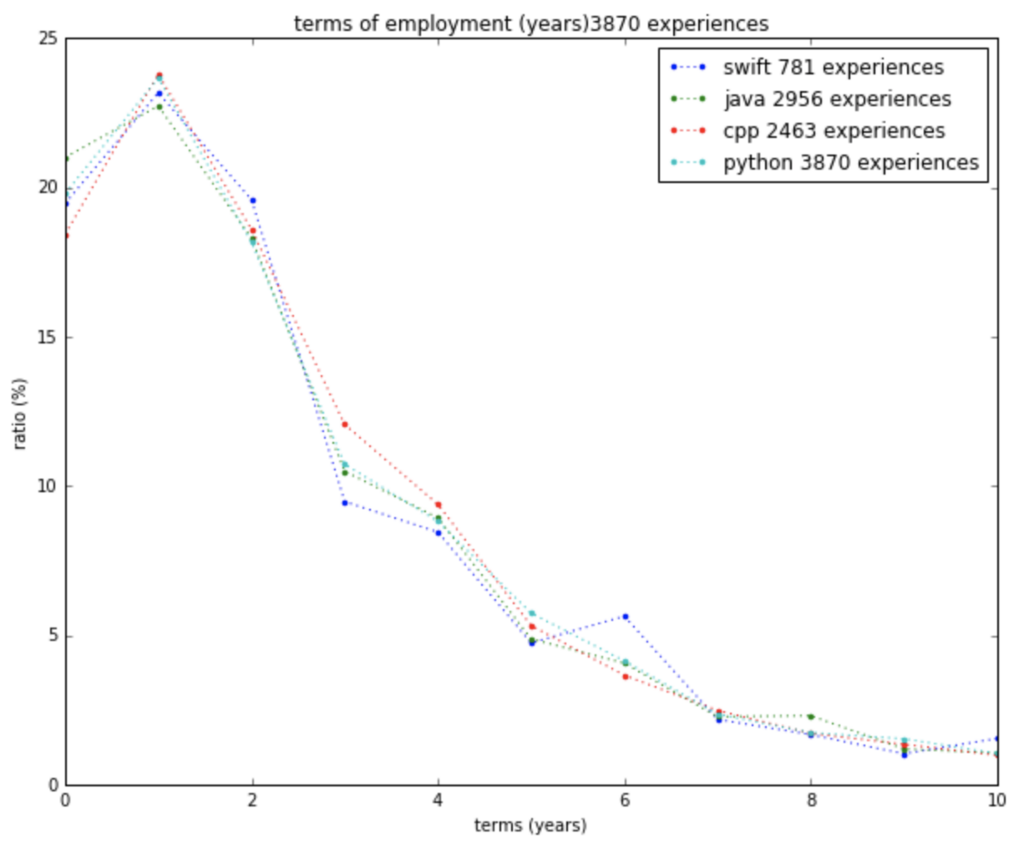
使用プログラミング言語ごとの勤務年数分布
逆に、分布に大きな差があるために積極利用していこうと確認できた属性は、「所属会社規模」で、下記のようにグラフごとに分布の差があることが確認できます。
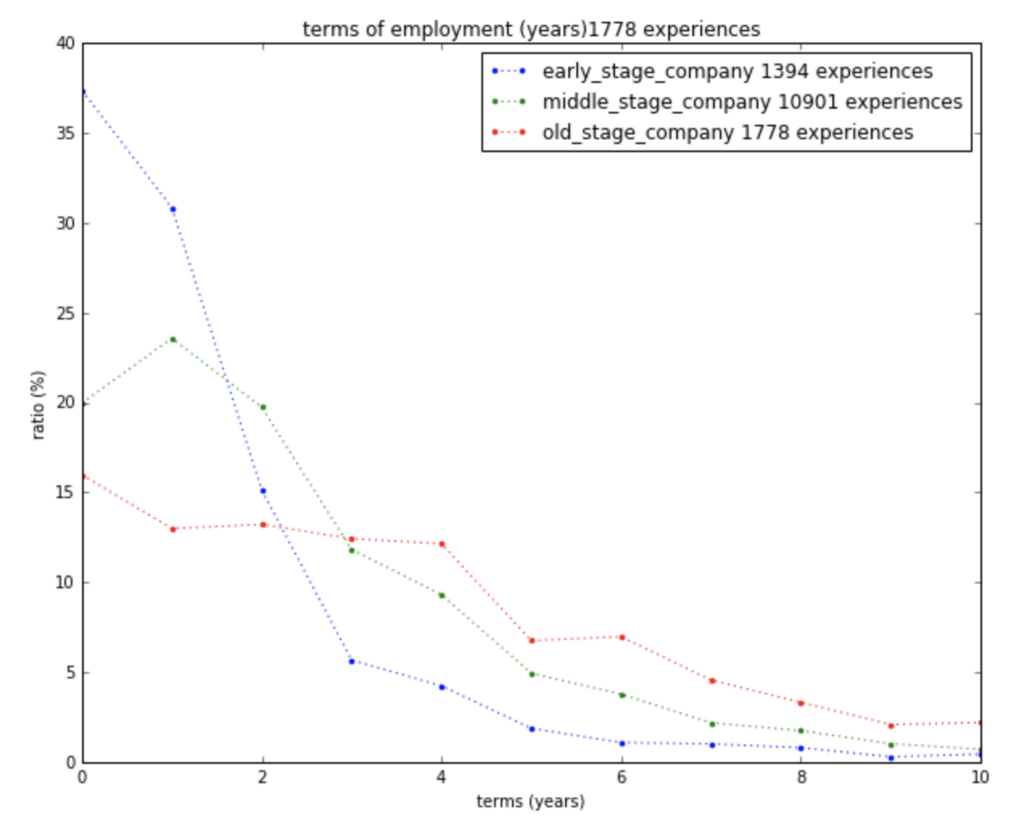
所属会社規模ごとの勤務年数分布
技術選定
技術選定自体は、実装するエンジニアとのディスカッションを通じて行われるべきですが、可能な選択肢のリサーチやそれぞれのメリット・デメリットの整理などはアルゴリズムマネージャが中心となってやるべきタスクとなります。 技術選定の基準は様々ですが、自分は以下の4つの基準を用いることが多いという印象です。(広告業界だと実行速度といった指標も入れるべきなので、ここはケースバイケースです)

もちろん、手法インプットとアウトプットが解きたい課題にフィットしているということが前提となります。学習データ量によっても手法ごとにパフォーマンス違う(少なくてもそこそこの精度が出る手法も、一定精度出すまでにかなりのデータがいる手法もある)ので、そういった点も考慮して手法を選定できればベストでしょう。 ビジネスでは必要なデータが貯まるまでに時間もかかったりもするので、「いついつまでに◯◯という手法を使い、その後は△△を使った実装に着手する」といったロードマップと合わせて検討するのが良いでしょう。
オペレーションの設計
新しいアルゴリズムを作ると、それに伴い実際のビジネスのオペレーションが変化します。例えば何かを自動化するアルゴリズムだとしたら、人手が不要になるので、その後の人の采配や、自動化した部分をどう運用していくかを考えなければいけません。転職可能性予測アルゴリズムの例では、「ラベル付けされた転職可能性で絞り込む」作業が顧客に発生するので、カスタマーサポートチームにその工程のサポートを加える必要がありました。(せっかく作ったアルゴリズムが顧客に利用されなければ無意味なので) アルゴリズムの開発に常にオペレーションの変化が発生するとは限りませんが、発生する場合は、アルゴリズムマネージャが率先してビジネス側の担当者とオペレーションを設計し、運用していかなければなりません。 また、アルゴリズムの保守の部分もアルゴリズムマネージャが担わなければいけません。データが変遷するとアルゴリズムの中身も変えなければいけないので、運用の型作りも作らなければいけません。(このあたりは手法が確立されている領域ではないので、作っていきたいですね)
アルゴリズムマネージャに必要な能力
以上をふまえて、アルゴリズムマネージャにとって必要なスキルセットは以下のようなものとなるでしょう。
- 各手法に関しての広い知識 (できれば実装経験があり、工数や必要なデータ量の肌感が掴めるのが望ましい)
- AI / ML系のライブラリ・クラウドサービスなどの広い知識(実装しなくて済む部分と実装が必要な部分の理解)
- CRISP-DM などのデータ分析のプロセスモデルへの理解
- クライアント・ユーザとの対話能力
- 経営や事業上のKPIへの理解
- 実装するエンジニアのマネジメント能力
知識が無いから、実装が苦手だからマネージャになるわけではありません。アルゴリズムマネージャがミスをすると、ビジネス上結果につながらないことを工数をかけて実行するといったことが発生するなど経営的にも大きなロスになるので、むしろ一番経験がある人がやるべきでしょう。
scoutyでは、アルゴリズムマネージャを募集しています。
データサイエンティストという職業はここ数年で浸透しましたが、アルゴリズムマネージャないしそれに類する役割は未だ必要性や仕事内容が認知されていませんし、仕事内容も曖昧なままです。scoutyでは、アルゴリズムマネージャの仕事をこなすと同時に、他社にも活かせる一般的な型やフローを構築し、それを世の中に発信していける人材を探しています。 現在は代表の島田がこれにあたる役割を兼任していますが、今後アルゴリズムも増えるにあたって専任の方を募集していく予定ですので、興味のある方は、下記のリンクから応募をお願いします!
また、今回のテーマ+α の内容は再度外部のイベントで発表予定です。イベントを共催してくれるの企業の方や、発表内容のリクエストなど、連絡やコメントお待ちしております!