こんにちは,松野です.本記事では,ツイートの情報からユーザーの職業を予測する実験を行った結果を紹介します.
はじめに
LAPRASではインターネット上に公開されているオープンデータを基に機械学習や自然言語処理の技術を用いてユーザーのスキルや志向性を分析し,それを活かしたマッチングシステムを作っています.
そういった分析に用いる基礎技術の一つとして,本記事では職業予測の実験に取り組みました.
実験設定などは先行研究である(Preotiuc-Pietro et al, 2015)を参考にしました.この論文では今回の設定と同じようにツイート内容等を用いてツイッターユーザーの職業を予測しています.
職業予測を適用可能な応用先
職業予測の技術は転職サービスを利用する転職希望者や採用担当者に以下のような便益をもたらし得ます.
転職希望者にとって嬉しいこと
転職希望者が求人情報や転職のサポートをうける機会を得るためのポピュラーな手段に転職サービスへの登録があります.LAPRASでも Matching Intelligence という転職マッチング・サービスのベータ版の実証実験に取り組んでいます.これは,従来転職エージェントによって行われていたキャリアマッチングを,Web上で自動化するシステムです.

情報入力の手間が省ける
新しい転職サービスに登録するとき,自分の情報を入力していくステップがあります.そういったときに,既存のSNSの情報から抽出や予測によって得られた情報を使うことで入力の手間を大きく削減できることが期待されます.その一つとして職業予測を使うことができます.
より多様な推薦が受けられる
いくつかの転職サービスはユーザーが入力した職業に基づいて求人情報を推薦します.それに加えて予測した職業も用いることで,ユーザーが入力していない職業の求人についても推薦を行うことができます.
採用担当者にとって嬉しいこと
LAPRASでは LAPRAS SCOUT というダイレクトリクルーティングサービスを提供しています.そのなかでも以下のような点で採用活動の効率化に役立てられます.

採用要件の決定に役立つ
採用活動の中には,採用要件を固め,それを基にアプローチすべき候補者を探すステップがあります.その時,ユーザーにおける職業の分布がある程度分かっていれば,実際にアプローチできる候補者のおおよその数を基に採用要件を考えることができます.
様々な粒度で検索ができるようになる
ある職業の人を探そうとするとき,ピッタリの能力や経歴を持っている人がいたとしても,その人のプロフィールに採用要件に書いてある職業名と同じものが書いてあるとは限りません.
例えば,Android エンジニアを探す時,求める能力を持つ人の全員が職業欄に「Android エンジニア」と書いていれば良いのですが,単に「エンジニア」と書いていることがよくあります.そういった場合でもブログやレポジトリなどのアウトプットを基に判断することはできますが,判断のためにはある程度の習熟が必要であり,労力もかかります.
こういうときに予測された職業ラベルがついていれば候補者を見つけるのにかかる労力は格段に低くなります.
実験
データ
今回の実験では,ツイッターユーザーのツイートを入力としてユーザーの職業を予測します.
なお,Twitter のプロフィール文やツイートは Twitter API を通して取得しています.
ここでは,ユーザーのプロフィール文に含まれる職業名をユーザーの職業としました.
例えば以下のようなプロフィールがあったとき,
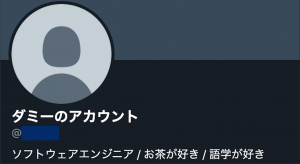
「ソフトウェアエンジニア」という職業名が含まれているため,このユーザーの職業ラベルは「ソフトウェアエンジニア」になります.
複数の職業名を含む場合は,一番はじめに出てきた職業名をユーザーの職業ラベルとします.
データ準備
データは以下の手順で準備しました.
- フォロワー数が500以上のユーザーのプロフィール文とIDを用意
- 内製の職業名辞書を用いてプロフィール文から職業名(ソフトウェアエンジニア,営業など)を抽出
- 職業名をプロフィールに含むユーザーの数などを基に分類の対象とする職業を選択
- 3. で選ばれた職業をプロフィール文に含むユーザーの最近1年間のツイートを用意
データセットに含まれるユーザー数は 2804 人,職業は 9 種類となりました.
これを訓練データと評価データに 3 対 1 の割合で分割しました.
分類器
今回の分類器には scikit-learn の LogisticRegression (ロジスティック回帰)を用いました.
また,ユーザーのツイート内容から名詞を抽出し TF-IDF 値からなるベクトルに変換したものを入力としました.
結果
分類性能
以下に分類結果を示します.
F1値のマクロ平均は 0.35 となりました.
| 全体の指標 | 適合度 | 再現度 | F1値 | 評価データ中の事例数 |
|---|---|---|---|---|
| 精度 | 0.36 | 701 | ||
| マクロ平均 | 0.36 | 0.38 | 0.35 | 701 |
| 重み付き平均 | 0.41 | 0.36 | 0.36 | 701 |
しかし,職業ラベル別でみるとスコアに大きなばらつきがあることがわかります.例えば,デザイナーと編集のF1値の間には40ポイントもの開きがあります.
| 職業ラベル別の指標 | 適合度 | 再現度 | F1値 | 評価データ中の事例数 |
|---|---|---|---|---|
| ソフトウェアエンジニア | 0.26 | 0.81 | 0.39 | 42 |
| デザイナー | 0.6 | 0.53 | 0.56 | 97 |
| マーケティング | 0.47 | 0.34 | 0.4 | 108 |
| ライター | 0.54 | 0.3 | 0.38 | 151 |
| 人事 | 0.48 | 0.43 | 0.45 | 51 |
| 企画 | 0.27 | 0.22 | 0.24 | 85 |
| 営業 | 0.26 | 0.36 | 0.3 | 67 |
| 広報 | 0.22 | 0.3 | 0.25 | 37 |
| 編集 | 0.16 | 0.16 | 0.16 | 63 |
職業別の重要語
今回実験に用いたロジスティック回帰では分類器中の各素性に対する重みをみることで比較的容易に素性の重要度を知ることができます.ここでは,職業ラベル別にどの語が重要とみなされたかをみていきます.
以下に各職業ラベルの予測において重要視された語をその重要度の降順で示します.
デザイナーでは上位に「デザイン,イラスト,サイト,UI」などデザイン関係の語が,ソフトウェアエンジニアでは「コード,アプリ,実装」などプログラミング関係の語が表れているなど,各職業の判定に必要そうな語が拾えていることがわかります.
しかし,ノイズとみられるような語(「の,そう,ん」等)も多く含まれています.テキストを処理する段階で名詞以外を除外するように簡単な処理は入れているのですが,ストップワードの除外などの処理をする余地も残されているようです.
| ソフトウェアエンジニア | デザイナー | マーケティング | ライター | 人事 |
|---|---|---|---|---|
| の | デザイン | マーケティング | ライター | 採用 |
| YouTube | デザイナー | 人 | 私 | 人事 |
| そう | ん | 広告 | さん | 会社 |
| in | ☺ | ビジネス | 記事 | note |
| 問題 | 感じ | 仕事 | ん | 方 |
| ん | design | こと | …。 | 組織 |
| コード | イラスト | 企業 | 更新 | 社員 |
| 感じ | 好き | これ | もの | by |
| エンジニア | 制作 | サービス | わたし | 面接 |
| アプリ | 絵 | 文章 | 募集 | |
| コメント | 色 | 事 | 取材 | 大事 |
| みたい | 前 | note | 本 | 自分 |
| 気 | サイト | コンテンツ | の | 企業 |
| 開発 | UI | ブランド | 言葉 | 学生 |
| 2 | 作業 | 顧客 | note | インターン |
| 時間 | やつ | s | 好き | ー |
| 実装 | 質問 | 化 | とき | チーム |
| 東京都 | ー | 行動 | 女性 | エンジニア |
| プログラミング | お | 会社 | 旅 | 新卒 |
| 英語 | フォント | 的 | たち | 株式会社 |
さいごに
本記事ではツイートの内容からユーザーの職業を予測する実験を行いました.今回は Twitter の情報だけを用いて荒い粒度の職業分類を行いましたが,今後の展開として Twitter 以外の情報を使ったり,より細かい粒度(フロントエンドエンジニア,データサイエンティストなど)での分類を行ったりすることが考えられます.
職業を含む人の属性の理解は人材業界において重要な基礎技術であるため,今後もこういった技術を洗練させていきます.
参考文献
Daniel Preot¸iuc-Pietro, Vasileios Lampos and Nikolaos Aletras, "An analysis of the user occupational class through Twitter content", "Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)"